1.실행 계획 (Execution Plan)이란?
SQL 쿼리를 실행하면 데이터베이스가 내부적으로 어떤 방식으로 쿼리를 처리할지 결정한다.
바로 이 처리 방식을 미리 계획한 것이 실행 계획 (Execution Plan)이다.
실행 계획을 보면:
- DB가 어떤 방식으로 데이터를 조회할지
- 인덱스를 사용할지, 테이블 전체를 스캔할지
- 얼마나 많은 데이터를 접근하는지
이 실행 계획을 통해 쿼리 성능을 점검하고, 비효율적인 부분을 발견해 쿼리를 튜닝할 수 있다.
실행계획 확인하는 방법
# 실행 계획 조회하기
EXPLAIN [SQL문]
# 실행 계획에 대한 자세한 정보 조회하기
EXPLAIN ANALYZE [SQL문]
예시로 해보면
EXPLAIN SELECT * FROM users
WHERE age = 23;
| id | 실행 순서. 복잡한 쿼리에서는 순서를 확인 가능. |
| select_type | SELECT의 타입. (JOIN, 서브쿼리 등 사용 시 확인) (처음엔 몰라도됨) |
| table | 조회 대상 테이블명 |
| partitions | 파티션 사용 여부 (처음엔 몰라도됨) |
| type | 어떤 방식으로 테이블의 데이터를 조회했는지 → ⭐️ 매우 중요 (ALL이면 풀스캔) |
| possible_keys | 사용할 수 있는 인덱스 목록 |
| key | 실제로 사용한 인덱스 |
| key_len | 인덱스 길이 (처음엔 몰라도됨) |
| ref | 조인 시, 어떤 값을 기준으로 조회했는지 |
| rows | SQL문 수행을 위해 접근하는 데이터의 모든 행의 수 (= 데이터 액세스 수) → ⭐️⭐️⭐️ |
| filtered | 필터 조건에 의해 최종적으로 몇 % 데이터가 사용되었는지 |
| Extra | 추가 정보 (Using where, Using index 등) |
👉 rows 값을 줄이는 게 SQL 튜닝의 핵심!
(단, rows/filtered 값은 추정치라 100% 정확한 수치는 아님.)
실행 계획 더 자세히 보기 예시
EXPLAIN ANALYZE SELECT * FROM users WHERE age = 23;
예시 해석:
- Table scan on users → users 테이블 전체를 스캔함 (Full Table Scan)
- rows=7 → users 테이블의 데이터 7개 모두 접근
- actual time=0.0437..0.0502
→ 첫 행에 접근하는데 0.0437ms, 마지막 행까지 읽는데 0.0502ms 걸림 - Filter: (users.age = 23) → age가 23인 데이터만 필터링 조건으로 걸림(뒤에 0.0552는 필터만 하는데 걸린 시간이 아닌 밑에 Table scan on users 까지 한거 합쳐진거다. 즉 필터만한 걸린 시간은 0.0552-0.0502 = 0.0050 이다
users 테이블의 모든 데이터를 스캔한 뒤, 그 중 age가 23인 데이터만 골라냈다.
이때 테이블 전체에 접근했기 때문에, 불필요한 데이터 읽기가 많을 수 있다.
2. 실행 계획에서 (ALL, INDEX) type 의미 분석하기
1️⃣ ALL: 풀 테이블 스캔 (Full Table Scan)
풀 테이블 스캔이란, 테이블 전체 데이터를 처음부터 끝까지 전부 조회하는 방식.
- 인덱스를 전혀 활용하지 않고, 테이블 전체를 하나하나 뒤져서 조건에 맞는 데이터를 찾음.
- 매우 비효율적.
- 테이블이 커질수록 스캔 비용도 커짐.
- 필요한 데이터가 소수라면 특히 낭비가 큼.

예시로 보면
EXPLAIN SELECT * FROM users WHERE age = 23;
`users` 테이블의 데이터는 `age`를 기준으로 정렬되어 있지 않고 `id`를 기준으로 정렬되어 있다. 그래서 `age = 23`의 값을 가진 데이터를 찾으려면 테이블의 처음부터 끝까지 다 뒤져봐야 한다. 그래서 실행 계획의 `type`이 `ALL`로 나온 것이다.
2️⃣ index: 풀 인덱스 스캔 (Full Index Scan)
풀 인덱스 스캔이란, 인덱스 테이블을 처음부터 끝까지 다 읽는 방식.
- 인덱스 테이블은 실제 데이터 테이블보다 크기가 훨씬 작음. → 따라서, 풀 테이블 스캔보다는 상대적으로 효율적.
- 하지만 인덱스 테이블 전체를 다 읽는 것이기 때문에, 여전히 최적이라고 할 순 없음.
예시로 100만개의 더미 데이터 넣고 name 컬럼을 인덱스 생성후 조회해보면
EXPLAIN SELECT * FROM users
ORDER BY name
LIMIT 10;
type: index인걸로 봐서 풀 인덱스 스캔을 했다. 즉, 인덱스를 처음부터 끝까지 다 읽어서 필요한 데이터를 뽑아냈다.
왜 인덱스를 풀 스캔했나?

- ORDER BY name 조건 → name 기준으로 정렬 필요.
- 이미 name 인덱스는 정렬되어 있음 (B-Tree 구조).
- 그래서:
- 큰 테이블(users) 전체를 정렬하지 않고, 인덱스 자체를 처음부터 끝까지 읽음.
- 인덱스에서 상위 10개의 name만 가져온 후, 그에 해당하는 row를 테이블에서 찾아옴.
3. 실행 계획에서 (CONST, RANGE, REF ) type 의미 분석
1️⃣ const: 고유 인덱스 또는 기본 키로 단 1건 조회
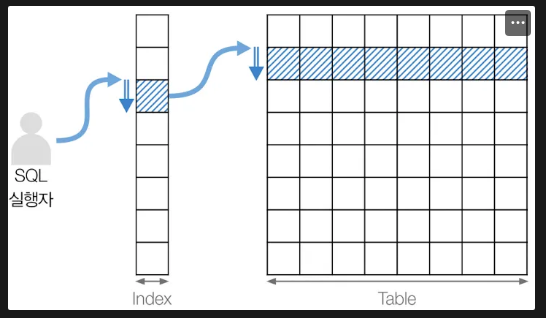
const는 1건의 데이터를 단번에 정확히 찾아낼 수 있는 경우에 표시된다.
주로 고유 인덱스(UNIQUE INDEX)나 기본 키(PRIMARY KEY)가 사용될 때 나타난다.
왜 const인가?
- 인덱스가 없으면 → 전체 데이터를 하나하나 다 뒤져야 한다.
- 비고유 인덱스면 → 조건에 맞는 값이 여러 개 있을 수 있어서, 다 확인해야 한다.
- 고유 인덱스 or PRIMARY KEY → 값이 유일함을 보장 → 1건만 찾고 끝난다.
가장 효율적인 방식으로 평가된다.
예시를 통해 (id,account 컬럼 테이블) 보면
CREATE TABLE users (
id INT AUTO_INCREMENT PRIMARY KEY,
account VARCHAR(100) UNIQUE
);
EXPLAIN SELECT * FROM users WHERE id = 3;
EXPLAIN SELECT * FROM users WHERE account = 'user3@example.com';UNIQUE 속성을 가진 컬럼은 인덱스가 자동으로 생성된다.
→ 두 쿼리 모두 type: const
(고유 인덱스 & PRIMARY KEY를 통해 단 1건만 바로 찾는다)
2️⃣ range: 인덱스 레인지 스캔 (범위 조회)

range는 인덱스를 활용하여 특정 범위의 데이터를 조회할 때 나타난다.
주로 이런 경우
- BETWEEN
- IN (...)
- 부등호 비교 (<, >, <=, >=)
- LIKE 'abc%' (접두사 매칭)
인덱스를 활용해 특정 범위만 스캔하므로 효율적이지만,
조회 범위가 너무 넓으면 데이터 접근량이 많아져 성능 저하의 원인이 될 수 있다.
예시를 통해(id,age 컬럼 테이블이고 age에 인덱스 설정,100만개의 더미 데이터 존재)보면
EXPLAIN SELECT * FROM users
WHERE age BETWEEN 10 and 20;
EXPLAIN SELECT * FROM users
WHERE age IN (10, 20, 30);
EXPLAIN SELECT * FROM users
WHERE age < 20;→ 모두 type: range로 표시된다.
3️⃣ ref: 비고유 인덱스를 활용하는 경우

ref는 비고유 인덱스( = UNIQUE가 아닌 컬럼의 인덱스를 사용한 경우)를 통해 특정 값 기반으로 인덱스를 조회하는 경우 나타난다.
주로 다음과 같은 경우에 해당한다.
- WHERE 절에서 특정 값 조건 (col = 값)을 줄 때
- 인덱스에 걸린 값이 여러 건일 수 있는 상황
- 조인할 때 특정 컬럼 기준으로 걸 때
예시를 통해(id,name 컬럼 테이블이고 name에 인덱스 설정했을시)보면
EXPLAIN SELECT * FROM users WHERE name = '박재성';→ type: ref로 표시된다.
🚩그럼 ref와 index의 차이?
| ref | 특정 값에 해당하는 인덱스 값만 조회 (부분 스캔) |
| index | 인덱스 전체를 처음부터 끝까지 스캔 (Full Index Scan) 예: ORDER BY, 정렬 목적, LIMIT 등에서 자주 등장 |
둘 다 인덱스를 사용하지만,
ref는 특정 조건으로 필요한 값만,
index는 인덱스 전체를 스캔하는 점이 다르다.
🔖 그 외 type들
eq_ref, index_merge, ref_or_null 등 다양한 타입들이 존재한다.
하지만 처음부터 모든 타입을 외우려고 할 필요는 없다.
실제 실행 계획에서 자주 보는 const, range, ref에 익숙해진 후, 더 깊게 공부하고 싶을 때 다른 타입들을 살펴봐도 충분하다.
📌 정리 표
| const | 고유 인덱스, 기본 키 → 1건만 조회 | 가장 빠름, 유일성 보장 |
| range | 인덱스 범위 조회 | BETWEEN, IN, 부등호, LIKE 접두사 등 |
| ref | 비고유 인덱스 조건 조회 | 특정 값 기준, 여러 건 가능성 |
| index | 인덱스 전체 스캔 | 정렬, LIMIT 등 인덱스 전체 훑음 |
'MySQL' 카테고리의 다른 글
| 5. SQL문 튜닝 연습-(2) (0) | 2025.03.18 |
|---|---|
| 4. SQL문 튜닝 연습-(1) (0) | 2025.03.17 |
| 2.인덱스 실전,멀티컬럼 인덱스 개념,실전 (0) | 2025.03.12 |
| 1.MySQL 성능 최적화에 대해,인덱스 개념 (0) | 2025.03.11 |



